

How did I do? Did I pass the test? Did I get an A?
We all like feedback and want to know how we performed in a scenario. Unlike our self-assessment of driving ability, or Deans’ letters of medical students, where we are all above-average, the assessment tools in OLab4 are a bit more objective. But learners want to know if they did well or at least well enough.
There are a number of ways in which to provide feedback in OLab4. Sometimes, you can just do this within the text of the story narrative: “Well done, you have reached the end. You survived the dragons!” etc.

The pathways and branches are an easy way to indicate to the learner when they are doing well or what they could have done better.
But sometimes you may want to leave that to the send. As well as the final text, you can also provide more specific data in the Session Report. This can provide very detailed information – how long you spent on each node, how your Counter scores changed, how your question responses compared with the ideal. Simply insert the shortcode [[REPORT]] into a Node at the end of your scenario.
Feedback within Questions
You will note when you are authoring your scenarios and map that certain Question types have a Feedback field, which can hold simple text. In single-choice and multiple-choice questions, each response item can provide Feedback.
If you select [Show feedback] = Yes, then the learner will be told immediately whether this response is correct or not.
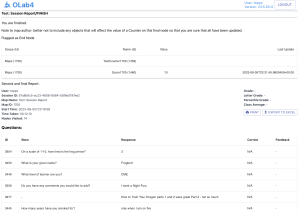
All the Question feedback is displayed in the Session Report, along with how the learner responded.
Feedback using Counters
Counters keep score. They are like programming variables and can be used for other purposes – see https://olab4.gitbook.io/help/basic-topics/objects#counters for more info. Counters can also be attached to Question responses.
A Counter by itself does not tell you much – you need to provide your learners with some context. What is an excellent score? What is good enough etc? These are even more effective when compared with the class cohort but this is a little harder to setup.
Changes from OLab3
In OLab3, there were several more ways of providing Feedback but these were little used and so have been deprecated in OLab4:
- Feedback on completion time
- Feedback based on Counter Scores
- Feedback based on Nodes visited, Must Avoid or Must Visit nodes
- Sliders had separate Counters and Feedback bands which were separate from the Slider index
- Situational Judgement and Script Concordance Testing
Drag and Drop Questions
The Question type where you can drag responses into a preferred order is quite popular with authors. But it is more contentious on how these should be scored. In OLab3, we used Fiona Patterson’s SJT scoring method, which has some advantages, but also some peculiarities.
We prefer relative scoring where some choices are better relative to others. But some psychometricians prefer a more absolute scoring method where you response order has to be the same as the expert, or you are just wrong. We are happy to explore these alternatives with other research groups.
Feedback on Free Text
While OLab4 can easily capture free text input, it is not so easy to provide helpful feedback on this. You might want to provide an exemplar e.g. a screenshot of a previous excellent response or an idealized example. You can ask the learner to reflect on their response, after they have been provided with some comparators.
You can also use TTalk options to gather and provide feedback on-the-fly. All the responses in a TTalk session are captured so you can ask the learner to reflect on how well the conversation went and what they could have done better. Or you can engage them in Think-Pair-Share exercises.
Learning the process, not getting the A
We do encourage authors to consider scenario designs that make learners think about the factors that they are considering, and the complexities of the decisions being made. Sometimes there is no single right answer. Indeed, in this world being changed by ChatGPT and other Generative Pre-trained Transformers, these AI-based engines are now excelling at passing simple fact-based testing. We need to move our assessment beyond simple fact recall.
Decision-making and problem-solving often involves grey areas and trade-offs. Some of our most interesting case series such as the DynIA project, or our family medicine Clerkship Cases, deliberately avoided having an ideal answer. They focused on problems where even the principle diagnosis was uncertain but you still had to decide on a course of action. Many students are uncomforable with this approach but it is a reality that all practitioners face.
However, even when there is no perfect answer, it is still important to provide feedback. This is sometimes hard to do well and makes for case designs that need considerable thought. OLab4 provides you with many options on how to do this.